Scraping Data Science Job¶
Untuk melakukan web scraping, kita gunakan library Scrapy. Scrapy adalah sebuah framework yang digunakan untuk crawl sebuah web dan mengekstrak data dari halaman web tersebut.
Tip
Perbedaan framework dan library terletak pada kontrol penggunaannya dalam sebuah program [Woz19].
Framework meminta kita untuk menyediakan apa saja yang diperlukan untuk menggunakannya.
Library mengizinkan kita untuk menggunakannya di manapun dan kapanpun.
Creating A Spider¶
Scrapy menggunakan istilah “spider” yang merupakan crawler utama untuk “merayapi” halaman sebuah web. Untuk itu, kita perlu membuat spider yang didefinisikan dalam sebuah class. Secara umum, struktur kode yang akan kita buat adalah seperti berikut.
import scrapy
from scrapy.crawler import CrawlerProcess
class DSJobCrawler(scrapy.Spider):
name = "ds_job_crawler"
# instructions for spiders to follow
...
# initiate CrawlerProcess
crawler = CrawlerProcess()
# assign which spider to use
crawler.crawl(DSJobCrawler)
# start crawling
crawler.start()
Imports¶
Pertama, kita lakukan impor framework scrapy dan class CrawlerProcess yang akan kita gunakan
import csv
import scrapy
from scrapy.crawler import CrawlerProcess
Kita hanya memerlukan 2 library saja, yaitu scrapy dan csv. Sebelum kita impor, kita harus pastikan bahwa scrapy sudah terpasang atau belum. Jika belum, kita bisa install terlebih dahulu.
pip install Scrapy
Tip
Untuk kemudahan, silakan akses notebook ini menggunakan Deepnote melalui link berikut: Web Scraping with Python
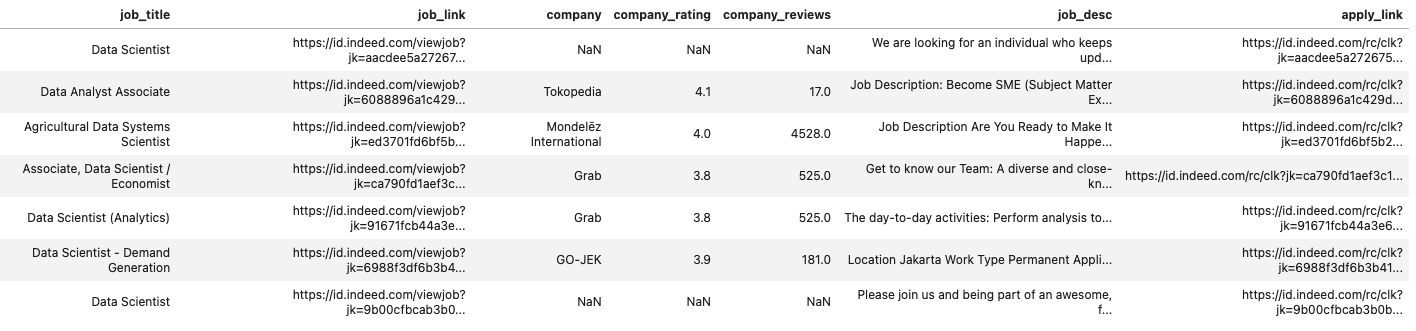
Supaya lebih sederhana, kita hanya akan mengumpulkan data lowongan pekerjaan data scientist dari Indeed. Data lowongan itu akan kita simpan dalam sebuah file berformat CSV, data_scientist_job.csv. Kita akan coba mengekstrak beberapa informasi berikut:
job_title→ Judul pekerjaanjob_link→ Tautan lowongan pekerjaan di Indeedcompany→ Nama perusahaancompany_rating→ Penilaian perusahaan berdasarkan pengguna Indeedcompany_reviews→ Jumlah ulasan perusahaan oleh pengguna Indeedapply_link→ Tautan untuk melamar pekerjaan
Oleh karena itu, terlebih dahulu kita buat file tersebut, data_roles_job.csv, yang hanya berisi informasi-informasi di atas menggunakan kode di bawah ini.
job_storage_file = "data_roles_job.csv"
with open(job_storage_file, "w") as out_file:
writer = csv.DictWriter(
out_file,
fieldnames=[
"job_title", "job_link", "company", "company_rating", "company_reviews",
"job_type", "job_location", "salary", "job_desc", "apply_link"
]
)
writer.writeheader()
Spider Class¶
Selanjutnya, kita buat class DSJobCrawler yang akan mengekstrak informasi yang disebutkan sebelumnya. Dalam mendefinisikan class tersebut, kita akan bagi ke dalam beberapa komponen:
Konfigurasi awal spider
Instruksi gateaway
Instruksi ekstraksi informasi
1. Konfigurasi Awal Spider¶
Pertama, kita gunakan kode di bawah ini.
class DSJobCrawler(scrapy.Spider):
name = "ds_job_crawler"
start_urls = [
"https://id.indeed.com/lowongan-kerja-data-scientist-di-Indonesia",
"https://id.indeed.com/jobs?q=Data+Science&l=Indonesia"
]
custom_settings = {"DOWNLOAD_DELAY": .25}
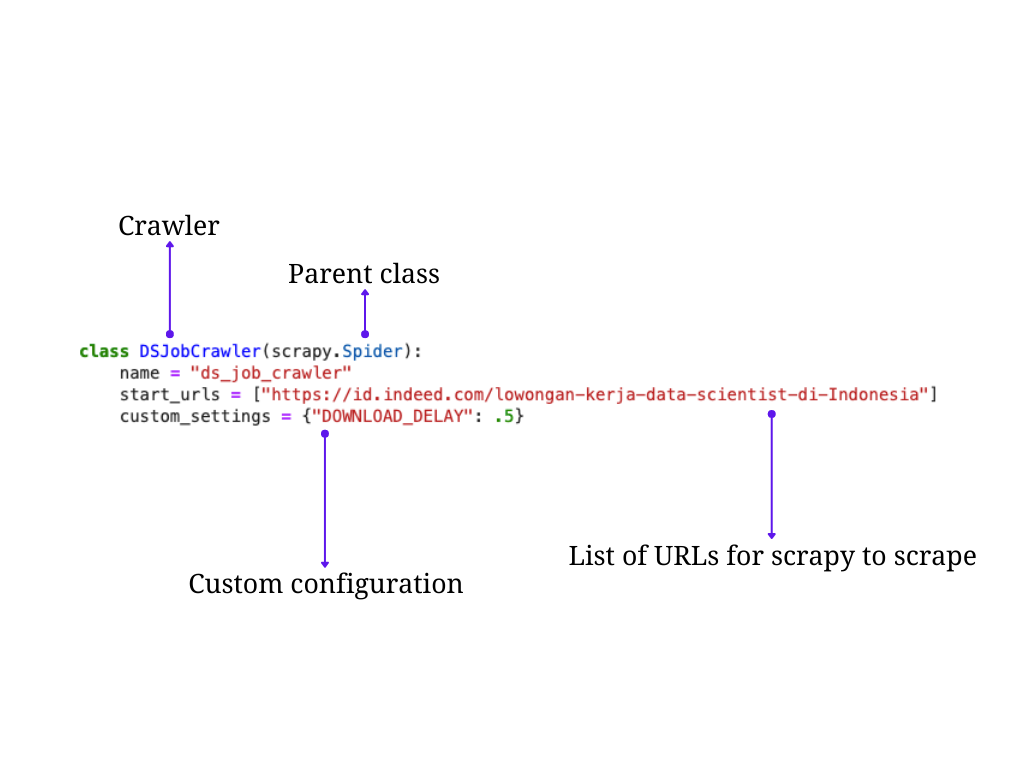
Fig. 7 Pendefinisian crawler¶
class DSJobCrawler(scrapy.Spider)→ class yang digunakan kita namai denganDSJobCrawleryang mewarisi classscrapy.Spider. Pewarisan (inheritance) ini wajib hukumnya agar scrapy bisa berjalan.Note
Penjelasan lebih lanjut tentang inheritance bisa dieksplor di artikel berikut.
name→ nama spiderstart_urls→ URL yang akan kita ekstrak informasinyaURL yang akan kita ekstrak informasinyacustom_settings→ konfigurasi pada spider yang nilainya kita tentukan sendirikonfigurasi pada spider yang nilainya kita tentukan sendiri
2. Instruksi Gateaway¶
Selanjutnya, kita akan mendefinisikan metode parse pada class DSJobCrawler yang pada kasus ini berfungsi sebagai sebuah gateaway. Maksud dari gateaway di sini adalah parse akan berfungsi sebagai gerbang masuk utama yang membantu mengarahkan tautan halaman yang akan diproses. Ini biasanya digunakan ketika kita tertarik untuk mengekstrak informasi dari beberapa halaman.
Sebagai contoh, jika kita lihat contoh tampilan halaman pada Indeed berikut, setiap halaman mempunyai daftar lowongan pekerjaan. Kita tertarik untuk mengekstrak informasi dari setiap lowongan yang ada di halaman 1, 2, dan seterusnya.
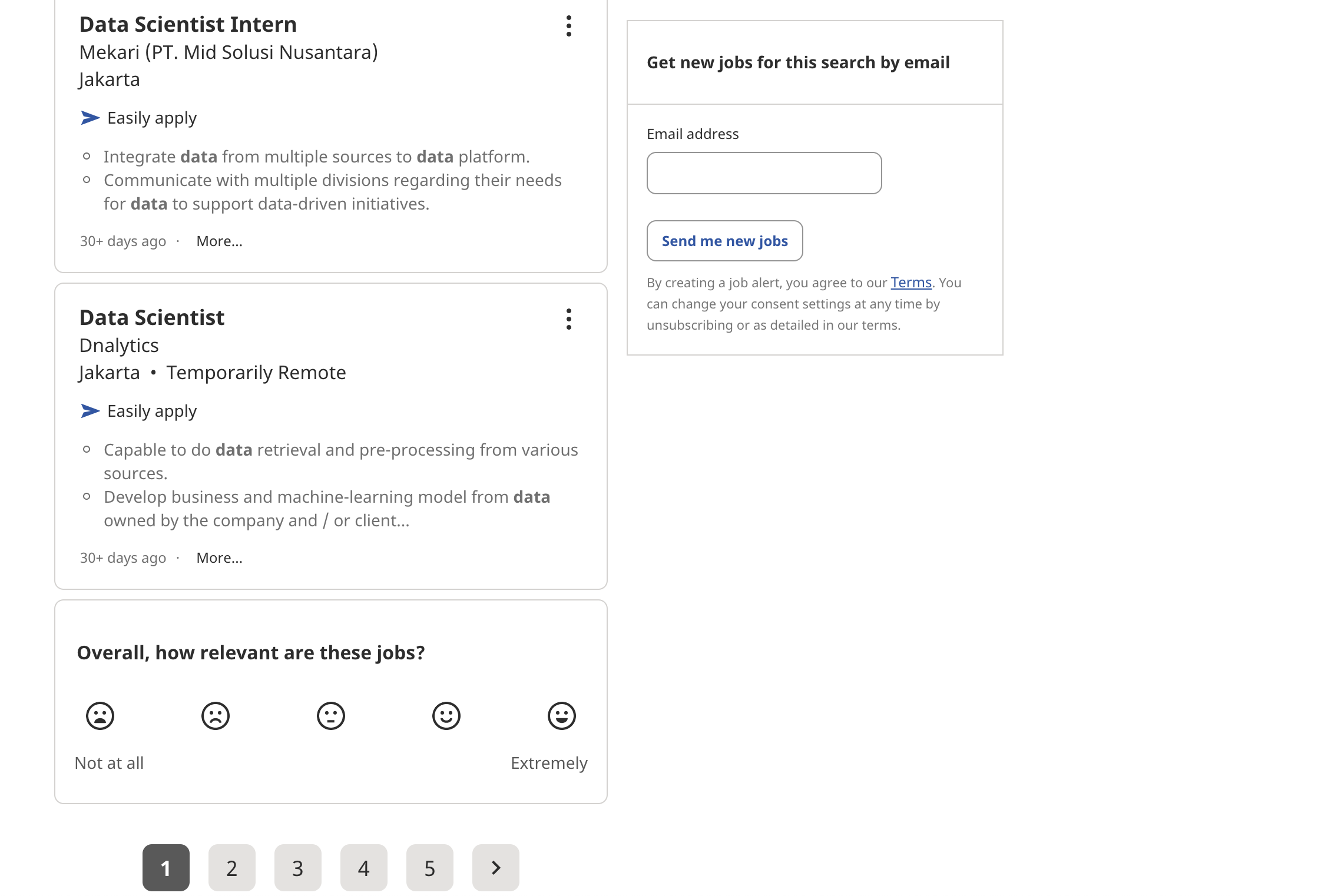
Fig. 8 Contoh tampilan laman Indeed¶
Kita akan menggunakan potongan kode berikut.
...
def parse(self, response):
current_page = response.css("ul.pagination-list").xpath(
".//*[contains(@aria-current, 'true')]"
).attrib.get("aria-label")
self.logger.debug("current page: %s", current_page)
try:
next_page = response.css("ul.pagination-list").xpath(
".//*[contains(@aria-label, '{}')]".format(int(current_page) + 1)
).attrib["href"]
except:
self.logger.info("Couldn't find next page. Done extracting")
else:
if current_page:
current_page += 1
yield response.follow(next_page, callback=self.parse, meta={"dont_redirect": True})
for job_link in response.css("a.tapItem::attr(href)").getall():
yield response.follow(job_link, callback=self.parse_detail)
...
Warning
... adalah kode sebelum dan sesudah definisi metode tersebut.

Fig. 9 Metode parse menerapkan fungsi rekursif untuk memroses tiap halaman dan mengarahkan ke metode parse_detail untuk memroses detil informasi lowongan¶
3. Instruksi Ekstraksi Informasi¶
Jika kita perhatikan pada metode parse di atas, ada bagian perulangan for job_link in response... yang menggunakan response.follow untuk meneruskan setiap tautan detail lowongan ke fungsi callback parse_detail. Metode inilah yang akan digunakan untuk mengekstrak semua informasi yang ada pada halaman detail lowongan pekerjaan.
Perlu diperhatikan juga bahwa setiap detail informasi pada lowongan pekerjaan pasti berbeda satu dengan yang lainnya, baik secara format penulisan dan kelengkapan informasi. Oleh karena itu, sangat wajar ketika informasi yang kita ekstrak tidak sempurna.
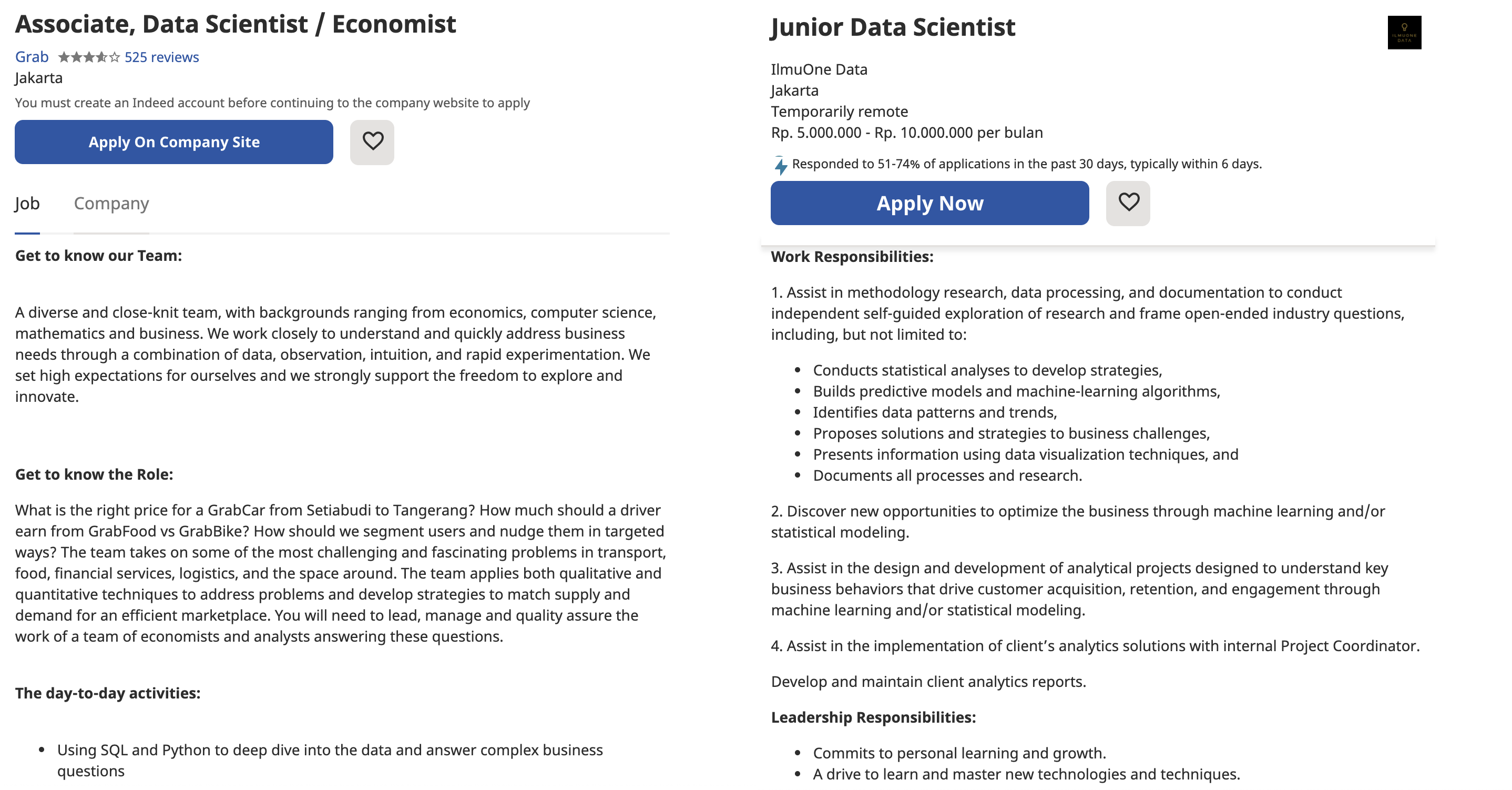
Fig. 10 (kiri) lowongan pekerjaan 1. (kanan) lowongan pekerjaan 2.¶
Untuk itu, kita gunakan kode di bawah ini.
...
def parse_detail(self, response):
company_info = response.xpath("//div[contains(@class, 'InlineCompanyRating')]")
list_job_desc = [
text.strip() for text in
response.xpath("//div[contains(@class, 'jobDescriptionText')]").css("::text").getall()
]
job_subtitle = [subtitle.get() for subtitle in response.xpath("//div[contains(@class, 'JobInfoHeader-subtitle')]/*/text()")]
job_detail = {
"job_title": response.css("h1::text").get(),
"job_link": response.url,
"company": company_info.xpath(".//a/text()").get() or company_info.xpath(".//div/text()").get(),
"company_rating": company_info.xpath(".//meta[contains(@itemprop, 'ratingValue')]").attrib.get("content"),
"company_reviews": company_info.xpath(".//meta[contains(@itemprop, 'ratingCount')]").attrib.get("content"),
"job_location": job_subtitle[0],
"job_type": job_subtitle[1] if len(job_subtitle) > 1 else "",
"salary": response.xpath("//div[contains(@class, 'JobMetadataHeader')]/span/text()").get(),
"job_desc": " ".join(list_job_desc),
"apply_link": response.xpath("//div[contains(@id, 'applyButtonLinkContainer')]").css("a::attr(href)").get()
}
if not job_detail.get("company"):
self.logger.debug("Got no company info: %s", response.url)
with open(job_storage_file, "a") as out_file:
writer = csv.DictWriter(out_file, fieldnames=job_detail.keys())
writer.writerow(job_detail)

Fig. 11 Metode scrape_detail melakukan pra-pemrosesan tag HTML, menyimpan dalam sebuah dictionary, yang kemudian disimpan dalam file CSV¶
Run The Crawler¶
Setelah semua komponen sudah siap dan dijadikan dalam satu class. Kita bisa langsung mengekstrak semua lowongan pekerjaan di Indeed menggunakan kode berikut ini.
crawler = CrawlerProcess()
crawler.crawl(DSJobCrawler)
crawler.start()